
Publicado en: UTMag/Rapozine http://www.UniversalThread.com/Magazine
Autor: Carlos Alejandro Pérez (Resistencia, Chaco, Argentina) QEPD - 26/07/1965 - 30/06/2021
La optimización
Mucho se ha escrito de la optimización Rushmore, característica inconfundible de FoxPro. Muchos programadores, incluso sin conocer profundamente a FoxPro, intuyen que es algo que tiene que ver con los índices, algo que acelera las consultas.
Pues entonces ¿qué es precisamente la optimización Rushmore? Podríamos decir, por ahora, que es la utilización de los índices para acelerar la recuperación de datos. Dicho así, nos quedamos con gran cantidad de preguntas sin respuestas.
Para entender un poco cómo funciona esto, demos un poco de base teórica la que seguramente no nos vendrá mal. Quizás algunas partes sean un poco difíciles de entender, pero por lo menos los conceptos al final de cada punto serán igualmente útiles para el lector. Tampoco espere el lector que se toquen todos los aspectos de Rushmore, debido a que Microsoft - como haría cualquier otro fabricante - no da mayores detalles de su arquitectura interna.
Jerarquía de almacenamiento
La jerarquía de almacenamiento se refiere a las distintas capas que tiene una computadora para almacenar información. En base de datos, la jerarquía es:
- Memoria RAM física. Poca capacidad (menor que 2 GB), gran velocidad (10ns). Volátil.
- Medio magnético de acceso aleatorio. Normalmente es un disco rígido. Capacidad intermedia (unos 50 GB), velocidad media (7 ms). No volátil.
- Medio magnético de acceso secuencial. Normalmente es una unidad de cinta DLT, DAT, etc. Gran capacidad (centenares de gigabytes) velocidad lenta (del orden de segundos a minutos). No volátil.
Por lo tanto, decimos lo siguiente: las bases de datos operan en la jerarquía 1 y 2. En la 1 se efectúa el PROCESO, en la 2 el ALMACENAMIENTO. De esto se deduce fácilmente que para que exista el PROCESO, debe transferirse información desde la jerarquía 2 a la 1, y viceversa. Volveremos sobre estos conceptos más adelante.
Modelo relacional
Como los sistemas de información hasta comienzos de los 70s eran propietarios, y sus datos se almacenaban en formatos también propietarios, se consumían muchas horas-hombre en alterar la funcionalidad de un sistema, ya que no existía una separación clara entre el programa y los datos.
Se necesitaba lo que se conoce como "independencia de datos", es decir, el programa debía estar protegido de los cambios que pudiesen haber en los datos. Para ello era claro que además del programa se necesitaba algo que estuviese separado del mismo: una base de datos. La base de datos provee independencia física, porque no importa cómo esté almacenada la información, ni el tamaño de las páginas, ni sobre qué soporte , el programa sigue viendo de la misma forma a los datos. También provee cierta independencia lógica, ya que el hecho de agregar columnas o procedimientos almacenados no debe influir sobre el programa preexistente (esto no es cierto, obviamente, si quitamos columnas, etc.).
Hasta esa época, los procesos en COBOL actuaban sobre archivos parecidos a los de texto, pero algunos usaban delimitadores especiales entre campos, otros utilizaban mecanismos de direccionamiento para saber dónde comenzaba y finalizaba cada campo, etc. Cada uno de estos mecanismos tenía limitaciones.
Ahora bien ¿qué es un modelo? Es un conjunto de conceptos utilizados para describir datos. ¿Y por qué relacional? Porque está basado en la teoría de conjuntos, donde el término "relación" se aplica a una asociación entre dos o más elementos de un conjunto. O sea una tabla.
El modelo relacional está basado en "tablas", las cuales son "relaciones". Esto debe quedar bien claro: las tablas son las relaciones. Cada tabla está compuesta de filas y columnas. Repitamos mentalmente: las tablas son relaciones. "Tabla" y "relación" son sinónimos.
La famosa "relationship" entre dos o más tablas NO es la relación que da el nombre al modelo relacional. Para eso, se utilizará el término vínculo, porque en español la traducción de "relation" y "relationship" conduce desafortunadamente a la misma palabra "relación". Por ello, la comunidad de habla hispana adoptó otros términos para referirse a "relationship", el más aceptado es "vínculo". Recordemos, pues, que el "modelo relacional" se llama así porque las tablas son relaciones.
El modelo exige que cada tabla debe necesariamente tener una clave. ¿Qué es una clave? Es el conjunto mínimo de columnas de la tabla que definen unívocamente la existencia de una fila. Por ejemplo, en una tabla PADRON la clave sería DNI, en una tabla ARTICULOS la clave sería (codigo_rubro,codigo_articulo), y así sucesivamente. Nótese que debe el conjunto "mínimo". En nuestra tabla PADRON, las columnas DNI y NOMBRE también definirían unívocamente la existencia de una fila, pero no sería un conjunto mínimo. Por esto se dice que DNI y NOMBRE no son una clave, sino una "superclave". En modelo relacional, las superclaves deben ser evitadas.
Las claves primarias, las candidatas, todas son claves. De esto se desprende que no pueden existir en el modelo relacional claves que sean repetidas, porque la definición prohibe esto. La clave primaria sería nuestro índice principal en VFP, la candidata nuestro índice candidato en VFP.
Esto deriva en una consecuencia insospechada: como dijimos recién, en el modelo relacional no es posible que los campos que conforman la clave se repitan. Si lo pensamos un poquito, esto da como corolario que que ninguna tabla puede tener dos filas idénticas.
Pero nosotros, viejos programadores de FoxPro, sabemos que esto no es así, que muchos de nuestros sistemas tienen filas duplicadas, y que muchas tablas tienen los campos clave duplicados. ¿Qué estará pasando? Lo vemos un poco más adelante.
El álgebra relacional
¿Por qué tanto alboroto con el modelo relacional? Porque era la primera vez que se describía una estructura de datos basándose en modelos matemáticos precisos. Como las tablas son "relaciones", las operaciones entre esas relaciones formó el llamado "álgebra relacional".
A ver si entendemos: así como existe una operación de suma para los números en el álgebra común, existe una operación de unión de tablas para el álgebra relacional. El álgebra común opera con números, el álgebra relacional opera con tablas. Así como el álgebra relacional devuelve resultados que son otros números, el álgebra relacional devuelve resultados que son otras tablas. Este es un concepto fundamental: los resultados del álgebra relacional son siempre tablas.
Entonces, hacia 1973 el modelo estaba completo. Se definieron cinco operaciones básicas para operar con las tablas, que formaron la base del álgebra relacional: selección, proyección, renombrado, reunión y unión. Cada operación actuaba sobre tablas, y devolvía necesariamente otras tablas.
Incluso para que el álgebra tuviese todas la operaciones, se derivó la operación de división entre dos tablas, un tanto exótica porque es la secuencia de varios operadores simples, y se la incluyó para que el modelo del álgebra fuese cerrado y completo (es decir, hubiera siempre una forma de recorrer el camino inverso en una cadena de operaciones, por lo tanto, para una multiplicación entre tablas - producto cartesiano - debería por lo tanto existir la división, etc.)
Si nos fijamos bien, no existe la operación de borrado. En efecto, la operación de borrado no se contempla en el álgebra relacional. Tampoco se contempla el "ordenado". ¿Y entonces?
Los lenguajes de bases de datos y la práctica vs. la teoría
El álgebra relacional dió paso a que D.D. Chamberlin, que trabajaba en los laboratorios de IBM en San José, California, hacia 1973, y otros, dieran los primeros bosquejos de SQL, el lenguaje estructurado de consulta. Entonces, por ejemplo, la operación de seleccion dió paso a la cláusula WHERE, la operación de proyección dió paso a la lista de campos que siguen a la cláusula SELECT, la de reunión dió paso a los JOINs en todas sus variantes, la de union a la SELECT... UNION... SELECT, y así sucesivamente.
Para cada operación del álgebra, los investigadores de IBM dieron nacimiento a comandos específicos que los cubrían. Había una equivalencia de 1 a 1 con el álgebra de tablas y los comandos de SQL.
El mundo de las bases de datos le debe mucho a IBM. Sin sus investigadores, SQL no habría visto la luz. En cuanto a herencia y linaje, IBM es la madre de todas las bases de datos. Por ejemplo, fué la primera en resolver consultas recursivas en implementaciones dede motores comerciales (la cláusula WITH RECURSIVE ya podía usarse en algunas versiones de DB/2 para mainframes) en épocas en que SQL 3 era sólo un sueño. Oracle sería protagonista recién varios años después.
Pocos años después, los investigadores se retiraron de IBM, y formaron su propia empresa: The Relational Institute. El mismo sigue hasta la actualidad, investigando los fundamentos matemáticos del modelo relacional, que parecen aún hoy no tener fin.
Existen sólo dos lenguajes "puros" para bases de datos relacionales puras: el SQL y el QBE (consultas por ejemplo), creado por M. Zloof en 1975. Los demás no implementan totalmente el álgebra relacional, aunque cueste creerlo. QBE es un lenguaje que utiliza una grilla para armar las consultas, y no es declarativo, sino que uno más bien rellena esa grilla de acuerdo de los criterios de filtrado, selección, etc, y el sistema ejecuta la consulta. Estuvo muy en boga hace unos años, pero actualmente está en desuso, totalmente superado por SQL.
El lenguaje de consultas estructurado, SQL, ha pasado a ser la base para variados dialectos. Existen tres normas ANSI que definene los alcances del lenguaje, que se identifican con niveles o con los años donde fueron promulgadas: nivel 1, para el año 1989 (SQL 89), nivel 2, para el año 1992 (SQL 92), y nivel 3 en 1999 (SQL 99).
Cada fabricante libera su dialecto SQL con un determinado grado de porcentaje de cumplimiento de la norma. De esta manera, tenemos que el fabricante XXX tiene un 80% de cumplimiento o adhesion a SQL nivel 2 (SQL 92), etc., y que el YYY tiene un 90 % de adhesión a la misma norma. Esto no indica que YYY sea mejor que XXX, sólo significa que son distintos. Idealmente, sería bueno que exista un 100% de adhesión a los estándares, pero eso es algo casi imposible de lograr, debido a que implementar toda la norma daría un gestor de bases de datos extremadamente caro de construir. Hoy en día, ninguna de las bases de datos cumple 100% todas las premisas del modelo relacional propuesto por ANSI, por ejemplo, nadie soporta el operador DIVIDE de división entre tablas, o el operador INTERSECT el cual no es soportado ni siquiera por Oracle. Existen caminos para llegar a lo mismo, pero son combinaciones de comandos más sencillos. Son, de hecho, soluciones de compromiso.
Un 80% de los fabricantes recién están dando un porcentaje de cumplimento razonable al nivel 2. Sólo unos pocos al nivel 3. Una honrosa excepción a la regla es la IBM DB/2, la cual tiene un alto grado de adhesión a estos estándares, como era de preveerse, cercano al 100%.También es de destacar el papel de la PostGRESQL, un gestor académico que tiene su versión en fuente abierta bajo licencia GNU, para el mundo de Linux, la cual es altamente compatible con el estándar, incluyendo algunas características de SQL3. Desafortunadamente, la IBM DB/2 es un gestor con una gran complejidad técnica, y la curva de aprendizaje es francamente empinada si uno desea sacarle todo su potencial. En nuestras pruebas, el SQL Server ha resultado ser un gestor liviano, rápido y eficaz a la vez que relativamente fácil de aprender, con performance igual o superior a su contrincante del gigante azul. Algunos colegas podrán seleccionar la profundidad y rigidez técnica de DB/2, mientras que otros se quedarán con la interfaz amigable e intuitiva de SQL Server. No estamos aquí emitiendo opinión alguna sobre las velocidades de estos gestores ni otros factores de performance, simplemente hacemos notar las distintas idiosincracias de dos contendientes mayores en la arena de las bases de datos, como lo son Microsoft e IBM.
Veamos un ejemplo de diferencia entre la teoría y la práctica: el modelo relacional establece que una tabla no puede tener dos filas exactamente iguales, porque esto impediría que exista una clave. Y no puede existir una relación sin una clave. Pero nosotros sabemos que en el mundo real eso no es así. El SQL Server permite generar tablas y cargar datos repetidos, lo mismo hace Visual FoxPro. ¿Qué sucede? Sucede que no hay un grado de cumplimento total con la teoría, que la práctica se aparta de la teoría. En las bases de datos, la práctica siempre está a una saludable distancia de la teoría. Esto siempre fué así, y por fundadas razones que veremos más adelante.
Otro ejemplo: el resultado de una operación de álgebra relacional debe ser otra relación que cumpla con el modelo. Por lo tanto, el resultado de una selección debe ser una tabla sin filas repetidas. Pero en el mundo real, tampoco es así: por defecto, el resultado de una consulta SQL-SELECT puede dar filas repetidas. Para evitar repetidos, debemos utilizar la cláusula DISTINCT y entonces cumplir con el modelo.
De estos ejemplos, se deduce que: los gestores comerciales de bases de datos en su comportamiento por defecto no trabajan totalmente de acuerdo al modelo, pero tienen mecanismos para forzar el cumplimiento del mismo si el programador así lo desea. Esto también es un concepto fundamental.
¿Qué es un optimizador?
El optimizador es la parte del gestor de bases de datos que se encarga de reducir al mínimo el traspaso de información de una jerarquía de almacenamiento a otra. En nuestro caso, minimiza el tiempo que se accede al subsistema de disco. Para lograrlo, existen diversos mecanismos que ayudan a que en tiempo en transferir la información de la jerarquía 2 (disco rígido) a la 1 (memoria RAM) sea el mínimo posible.
¿Porqué no optimizamos el acceso a la RAM? Porque el tiempo de acceso al disco es varias magnitudes más grande que el acceso la RAM. Suponiendo tiempos promedios, para una SDRAM típica oscila en unos 10 ns (10-9 seg.), mientras que para un disco rígido oscila en unos 5 ms (5x10-3 seg.). Nótese que existe una diferencia del orden de seis magnitudes (106) entre ambos. Por lo tanto, se gastan todos los recursos de lógica de programación en acortar el tiempo de acceso al disco, con ello se tiene más del 90% de la ganancia posible.
Cuando un gestor de base de datos accede al disco, efectúa una serie de operaciones que se conforman un método de acceso. El optimizador simplemente altera el método de acceso con un sólo objetivo en mente: minimizar el tiempo que duran sus operaciones.
Los índices: qué son y qué no son
Entonces llegamos al punto de tener que preguntarnos ¿qué son los índices? ¿Son necesarios?
- La respuesta es desconcertante: NO. Cualquier sistema de bases de datos relacional debe poder funcionar sin los índices.
Entonces la pregunta de rigor es ¿para qué sirven los índices? ¿sirven para ordenar?
- La respuesta es aún más desconcertante: Los índices NO sirven para ordenar. Su cometido es otro.
Entonces, veamos precisamente lo que es un índice y para qué existe:
- Un índice es una estructura externa física de una tabla.
- No forma parte del modelo relacional, ni del álgebra relacional (por eso cualquier motor de bases de datos debe servir aún sin tener un sólo indice definido).
- Su único cometido es acelerar el acceso a los datos. El gestor de base de datos los utiliza para alterar su método de acceso.
- El hecho que eventualmente ordenen datos es un efecto casual de cómo están estructurados los índices.
- Los índices son tablas, por lo tanto, los índices también son relaciones.
- Los indices tienen dos columnas: una columna, la primera, contiene el valor de la clave, en el caso del índice se llama "clave de búsqueda". Por ejemplo, si tenemos un indice por codigo_articulo+codigo_sucursal, en la primera columna irán todos los valores de esa expresión. En la segunda columna se graba lo que se conoce como RID (record identification). El RID es un par ordenado de números enteros, el primer número indica el número de la página del archivo de la tabla donde se encuentra el registro que tiene la clave grabada en la primera columna, el segundo número indica la posición del registro dentro de la página. Existen otras organizaciones más complicadas, pero todas son derivadas de este concepto de< pagina,RID>.
Tipos de índices en gestores convencionales
Estos conceptos que se indican a continuación son aplicables a bases de datos relacionales en general. Más adelante veremos que sólo son implementables en bases de datos servidoras, en las de escritorio, tales como VFP, se utilizan derivados de estas aproximaciones.
Todos los índices sirven para lo mismo: acelerar el acceso a los datos. ¿Cómo hacen esto? Del mismo modo que el índice de un libro: si queremos leer un segmento del libro, buscamos primero en el índice. Si el libro no tuviese índice, deberíamos explorar todas la páginas desde el principio hasta hallar lo que necesitamos. Con las tablas pasa lo mismo. Ante la carencia del mismo, el gestor deberá "escanear" todas las páginas del archivo de la tabla para encontrar el registro deseado.
Existen dos tipos de índices:
- Indices clustered o agrupados. El índice clustered tiene una característica: hace ordenar físicamente al archivo de la tabla de acuerdo al ordenamiento interno del propio índice. En otras palabras, si tenemos un indice 'clustered' por nombre de una persona, la tabla misma se ordenará alfabéticamente por esa columna.
- Indices normales (esto siempre referido a gestores de bases de datos servidoras, no de escritorio, veremos luego las diferencias, pero por ahora los conceptos son genéricos para bases de datos relacionales servidoras). Son los que no son clustered, aunque esta es una clasificación muy general, servirá para nuestros propósitos.
Nosotros dijimos que el ordenamiento es un resultado colateral del índice. La razón de esto es la siguiente: para ubicar un dato en un índice, es necesario utilizar algún algoritmo. El más adecuado fué en su momento el llamado de "busqueda binaria", y consiste en:
- Ir a la mitad del índice, y preguntar si el valor que estamos buscando es menor que la clave de búsqueda en la mitad del archivo.
- Si es menor, entonces descartamos la mitad inferior del archivo del indice, porque sabemos que el dato buscado estará en la mitad superior.
- Si es mayor, entonces descartamos la mitad superior del archivo de índice, porque sabemos que el dato buscado estará en la mitad inferior.
- Luego vamos a la mitad del segmento que quedó remanente, y repetimos la pregunta. Este mecanismo se repite hasta que se produzca la coincidencia.
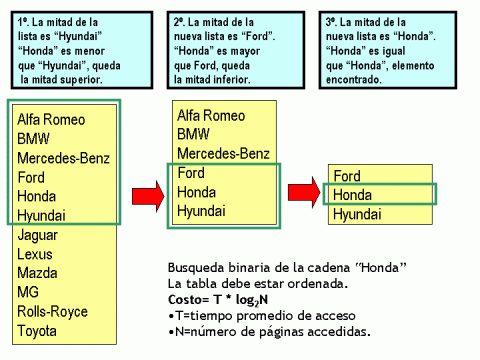
Figura 1: Búsqueda binaria simple.
El tiempo que se necesita para encontrar un dato es uno de los menores posibles, siempre y cuando la tabla que representa el índice esté ordenada. Si la tabla que contiene al índice no está ordenada, la búsqueda binaria no sirve, no funciona. Es por esta razón que los archivos de índices están ordenados, pero esto es una necesidad del algoritmo de búsqueda binaria, no el fin primordial del índice.
Una vez que se ubica el RID en la tabla del índice, es relativamente rápido ubicar el registro de datos de la tabla verdadera.
La pregunta normal sería entonces: ¿porqué no hacemos una búsqueda binaria en las tablas, de esa manera nos evitaríamos el índice? La respuesta es que eso sería aplicable si sólo existe un índice por tabla, pero si llegamos a necesitar cinco índices sobre una misma tabla, es inaplicable. Por lo tanto, se necesitan archivos que sean externos a las tablas - los índices.
Otro concepto fundamental: como el índice tiene menor cantidad de información que la tabla propiamente dicha, es mejor buscar primero en el índice que en la tabla, ya que hay que transferir menor cantidad de información del disco a la memoria para ser procesada.
Como el índice clustered ordena la tabla física de acuerdo a su propio ordenamiento, es que sólo puede existir un índice clustered por tabla (obviamente, una tabla no puede estar físicamente ordenada por dos o más claves distintas al mismo tiempo). Entonces, dentro de los índices, el clustered será el más veloz, ya que la tabla mantiene el ordenamiento igual que el índice. El resto de los índices tendrán un rendimiento menor. Por esta razón, cuando se define una clave primarial en una tabla de SQL server, el gestor automáticamente impone un índice clustered en virtud de su mayor rendimiento.
El optimizador y el plan de acceso
Dijimos que el optimizador minimiza tiempos. Hablando en la jerga de los gestores de bases de datos, diremos que minimiza el "costo" de la consulta para que sea el menor posible. El método que se usa para acceder al disco se llama "plan de acceso". Una consulta puede tener una infinidad de planes de acceso, el tema es encontrar el mejor de todos ellos, es decir, el que involucre el menor costo.
¿En qué se mide el costo de la consulta? Inicialmente se medía en ticks del microprocesador, mientras más ticks necesita más cara será la consulta. Actualmente, se definen otras unidades de medida. Las más modernas involucran tiempo de acceso al disco, velocidad del frontside bus del procesador, velocidad de la RAM, velocidad del procesador, etc., así algunos gestores definen unidades de medida abstractas. Por ejemplo, en la DB/2, los ingenieros de IBM definieron una unidad de medida llamada "timeron", etc.
De todos modos, recordemos que más del 90 del tiempo gastado en una consulta se consume en el subsistema de disco. Por lo tanto, de poder minimizar el tiempo de acceso al disco, estaríamos optimizando en gran medida el costo de la consulta. Esto es lo que hacen la mayoría de los gestores en primera instancia, de eso se encarga primordialmente el optimizador.
Existen entonces distintos tipos de optimizadores:
- Automáticos o heurísticos: constantemente intentan optimizar la consulta. Para ello disponen de una base de conocimientos provista por el fabricante, y celosamente programada en el motor de la base de datos, y de un motor de inteligencia artificial - aunque usted no lo crea, es básicamente una red neuronal. Supongamos que una consulta complicada tenga 100 formas distintas de ejecutarse. ¿debería el optimizador averiguar cuál es la optima? Si lo hiciere, gastaría más tiempo averiguando la solución perfecta que ejecutando dicha solución. Por lo tanto, en motor de inteligencia artificial lo que hace es: buscar una solución aceptablemente buena (heurística) en un tiempo tal que no comprometa el gasto total. De esas 100 formas, sólo examinará 5 ó 6. Posiblemente la solución no sea perfecta, pero como no se consume mucho tiempo decidiendo cuál usar, el tiempo total se ve optimizado. Funcionan en tiempo de ejecución. Los más avanzados efectúan una reescritura de la consulta, de tal manera que uno nunca está seguro si la consulta que se escribió es la que realmente se ejecuta.
- Por sintaxis o código: depende del programador. Las consultas deben escribirse apropiadamente para que el gestor de base de datos utilice la optimización. Es obviamente, en tiempo de diseño. El ejemplo más claro es la correcta escritura de las expresiones básicas optimizables de Rushmore.
- Por asistentes: lo que hacen en realidad es optimizar el código a través de un asistente, en tiempo de diseño. Es una variación del segundo. Generalmente son interfaces gráficas que descomponen la consulta en sus procesos básicos, y los muestran en una especie de flujograma con símbolos geométricos sencillos. Cada símbolo representa un proceso primitivo o básico del gestor de bases de datos, y por cada uno se evalúa un costo. El programador deberá examinar este diagrama y determinar dónde está el cuello de botella de su consulta, para adicionar índices, etc. Algunos asistentes hacen sugerencias acerca de los índices que faltarían para mejorar la consulta.
Los optimizadores automáticos están en todas las bases de datos servidoras, y los fabricantes jamás revelan mucho acerca de cómo funcionan, porque ese es su secreto. El del SQL Server es ciertamente refinado y poderoso, si bien gran parte de su actividad es secreta y en segundo plano. También depende de estadísticas recolectadas a través del tiempo que ayudan al motor de decisión a encotrar rápidamente una solución aceptablemente buena.
Existen otros métodos de mejora de tiempo de respuesta, pero no actúan sobre el costo de la consulta, sino reasignando los recursos de procesador y memoria al gestor de base de datos a través de mecanismos de "paralelización". En efecto, aunque el equipo disponga de un sólo procesador, algunos motores de bases de datos permiten ejecutar en paralelo ciertas partes de la consulta (paralelismo intra-consulta - intraquery parallelism). Uno de los ejemplos más notables es el Oracle, donde se puede exigir que determinada consulta se ejecute en paralelo insertando ciertas directivas (hints) entre delimitadores especiales en el código de la consulta. Estas directivas se evalúan por el compilador, y se ejecuta en paralelo. El preprocesador del compilador decide qué segmentos de código son aptos para paralelismo. En nuestras pruebas, en un padrón de 1.980.000 registros, sin índice alguno, sin paralelismo (funcionamiento normal) el Oracle 8.0.x arroja un tiempo de 1 (20 segundos), con paralelismo activado - limitando a 2 procesos paralelos en la consulta - el resultado es de 0,4 (8 segundos), es decir, un ahorro de tiempo de 60%.
Microsoft sin duda no se quedará atrás, pronto alcanzará este tipo de sofisticación, las nuevas versiones de SQL prometen ser las mejores bases de datos jamás construidas. Recordemos además que VFP y SQL Server tienen una perfecta sinergia para construir sistemas, y SQL Server las menores tasas de consumo de recursos - eso lo hemos comprobado.
Optimizaciones en VFP
En Visual FoxPro, como en casi todas las bases de datos de escritorio (las que no son client-server), no existe el concepto de índice clustered. Las tablas por lo general son archivos de registros desordenados (heap-files), es decir, no tenemos porqué asumir que las tablas de VFP deban estar ordenadas, a diferencia de las de SQL Server, IBM DB/2 u Oracle, donde de existir una clave primaria, se presume la existencia de un índice clustered que ordena físicamente la tabla.
Nosotros podemos emular la existencia de índice clustered en VFP corriendo periódicamente el comando SORT sobre los campos de la clave del índice, y crear sobre la nueva tabla los índices que ésta tenía, pero hasta allí podemos llegar.
En VFP existen tres tipos de optimizaciones: (1) la automática, (2) la explícita, por código del programador, y la (3) implícita, que opera sobre las marcas de borrado. Lo que sí es automático es la utilización de los índices si el optimizador encuentra una cláusula correctamente escrita.
Optimización automática
- VFP evalúa si existen algún índice creado que coincida con la cláusula WHERE o FOR. Si existe, utilizará los índices.
- Si no existen, evaluará el tiempo de imposición de los índices. Si el tiempo estimado para crear un índice sobre la clave de búsqueda definida en la cláusula WHERE o FOR es menor que el tiempo para ejecutar la consulta, VFP creará primero un índice temporal y luego ejecutará la consulta sobre ese índice. Para tomar una decisión, primero debe medir el tiempo de acceso al disco, la cantidad de memoria disponible, la cantidad de disco libre, el número de filas a indexar, etc. Los índices temporales se almacenarán en el directorio definido por TMPFILES en CONFIG.FPW, o en el directorio temporal por defecto dado por la función SYS(2023) en Visual FoxPro.
- Es poco probable que sea una optimización heurística tal como la que presentan las bases de datos servidoras, debido al reducido tamaño del motor VFP es que seguramente será un algoritmo más directo y compacto. Creemos más bien que todo el esfuerzo fué puesto en el mecanismo de indexación, y de recuperación y evaluación de índices, con un algoritmo ultra veloz - el mejor de la industria. Sin embargo, esto son sólo especulaciones basadas en la poca evidencia que podemos ver desde el exterior.
- VFP No presenta mecanismo de almacén de estadísticas, ni mantiene registros de planes de acceso de las consultas efectuadas, por lo tanto, es casi seguro que no existe una heurística basada en tal base de conocimiento.
Como era de preveerse, ni Fox Software ni Microsoft han dado mayores detalles acerca del mecanismo de decisión de optimización de VFP.
Optimización explícita
La optimización explícita consiste en hacer coincidir la expresión de una cláusula de comparación FOR o WHERE con la expresión con la que se construyó un índice. Es decir, el programador explícitamente optimiza el código de consulta o de comandos xBASE. Si se cumplen ciertas condiciones entonces es de uso automático.
Por ejemplo, si se ha creado un índice con:
INDEX ON codart+codsuc TAG i1
Lo correcto es hacer una consulta tal como
SELECT * FROM artic WHERE codart+codsuc=lcArtic
lo cual quedaría correctamente optimizada, y lo incorrecto sería hacerlo sobre
SELECT * FROM artic WHERE codart=lcArtic
en cuyo caso, al no encontrar VFP una expresión explícitamente optimizada, intentará imponer una optimización automática. Nótese que para que la sentencia
SELECT * FROM artic WHERE codart+codsuc=lcArtic
sea efectiva, la comparación ANSI debe estar en OFF, de otra manera, para que la igualdad devuelva TRUE, ambas cadenas deberán tener el mismo largo (asumiendo comparaciones de cadenas), y en general devolverán FALSO porque lcArtic es una variable de memoria que contiene sólo una parte de la clave de búsqueda la cual contiene aquí 2 campos.
Optimización implícita
La optimización implícita actúa sobre la marca de borrado. Para ello, cada tabla que participa de una consulta, de un filtrado o de un comando que acepte cláusula FOR, deberá tener un índice sobre la marca DELETED(). Por ejemplo, un índice tal como:
INDEX ON DELETED() TAG deltd
debe existir en cada tabla del sistema que participe en consultas o filtrados para que efectivamente ocurra la optimización implícita.
Esto es así porque el motor de optimización Rushmore agrega invariablemente una cláusula invisible si SET DELETE está en ON:
...AND NOT DELETED()
Por lo tanto, de tener ese índice disponible, se lo utilizará y la consulta será 100% optimizable. En otras palabras, la optimización implícita siempre está presente. De esto se desprende que todas las optimizaciones de código explícito que podamos escribir no serán 100% optimizadas a menos que exista el índice sobre DELETED(). Nótese que en las bases de datos cliente-servidor, no existe el concepto de marca de borrado porque en el álgebra relacional no hay tal concepto: o un conjunto tiene un elemento, o no lo tiene.
Si hablamos estrictamente, las bases de datos client-server también utilizan marcas de borrado, pero lo hacen autónomamente, y el usuario no puede interactuar con la misma. Las marcas de borrado se almacenan en un lugar de la página, y al conjunto de estos datos se le da el nombre de "mapa de bits". Cada bit representa una fila dentro de la página, de acuerdo a su posición dentro del mapa. Cuando existe un TRUE, el registro correspondiente tiene datos válidos. Cuando está en FALSE, el registro correspondiente está vacío o tiene datos que son "sobreescribibles", pero para el usuario final, esos datos no están disponibles, están efectivamente borrados.
¿Cuando no se puede optimizar con índices?
Cuando VFP determina que no se puede optimizar, no le queda otro camino que escanear (explorar) todas las páginas del archivo. Desafortunadamente, este es un proceso lento, ya que debe cargar todas las páginas en la memoria y esto consume gran cantidad de tiempo.
Existen mecanismos para optimizar el acceso a las páginas aunque no se disponga de un índice. Uno de los más utilizados es el mecanismo de archivo disperso (hashed file). El motor de base de datos implementa una función de dispersión (hash function) representada para nuestros propósitos como H(). El argumento de H es el dato que deseamos ubicar, y la función devuelve en forma de número entero positivo una posición posible del dato.
Por ejemplo, H("carlos") puede devolver 1632. Este número representa un conjunto de páginas o bucket (cubo). Si las páginas 200,201,202 y 203 tienen número de bucket 1632, entonces el motor de base de datos busca en esas 4 páginas y no en todo el archivo. Cuando se crean las tablas el gestor de bases de datos ya crea las mismas asociadas a los buckets iniciales.

Figura 2: Archivo disperso.
El truco está en programar la función de dispersión H para que no se produzca un congestionamiento de páginas y que se direccionen los datos parecidos al mismo bucket. Si esto sucediese se corre el riesgo de que la función de dispersión mande a buscar los datos en demasiadas páginas a la vez, y entonces perdería razón de ser. Esto se evita con una cuidadosa programación del algoritmo en la función de dispersión, la cual suele ser inescrutable y bastante complicada, a la vez que veloz.
Desafortunadamente, no creemos que VFP utilice esto en las tablas -Microsoft nunca dijo nada al respecto- ya que el método de dispersión necesita más almacenamiento que una base de datos regular. Por ejemplo, si una tabla ocupa 100MB, con el archivo disperso ocuparía 125MB, ya que el 25% se mantiene siempre como buckets de reserva. El motor de base de datos reserva este espacio en el mismo momento que se crea la base de datos. Como VFP no utiliza un contenedor físico centralizado - todas son tablas sueltas que se presentan logicamente unidas al estar presente una DBC - lamentablemente el método de dispersión no es aplicable. Como sabemos, la base de datos de VFP es un contenedor lógico, no físico, (eso significa que no existe como unidad sino desde dentro de VFP). Como contrapartida, una base de datos servidora normalmente tiene asociado un espacio de tablas (tablespace), el cual normalmente es un archivo, directorio o volumen unitario - puede después adicionarse más elementos al mismo espacio de tablas.
Algunos motores de bases de datos aplican el mismo concepto de archivo disperso a los mismos índices (porque después de todo, los índices también son tablas), dando aún más rendimiento a los índices normales, y utilizan un algoritmo de busqueda binaria aplicable sólo a un subconjunto de páginas.
VFP, en cambio, adopta otra filosofía. Por compatibilidad, la forma de almacenar los datos deben ser archivos DBF sueltos - sino, no sería FoxPro. Esto elimina la posibilidad de utilizar archivos de dispersión, y sólo deja la opción de utilizar lo más eficientemente posible los índices cuando se desee optimización.
NOTA: No debemos confundirnos con las operaciones de JOIN resueltas mediante estructuras de dispersión (hashed joins), que son mecanimos que permiten resolver JOINs entre tablas con mucha eficiencia. Este tipo de JOINs utilizan una tabla de dispersión en memoria. En el párrafo anterior, nos estábamos refiriendo a archivos almacenados en el disco con estructura dispersa (hashed file), no a la operación JOIN basada en esta técnica. La explicación de cómo funciona esta clase de JOINs va más allá del propósito de esta nota, y posiblemente será tema para futuros documentos. De hecho, nosotros creemos que VFP puede ejecutar algo parecido a hashed JOINS si ciertas condiciones se cumplen- aunque por supuesto, son sólo inferencias.
Por lo tanto, de no existir índices, VFP no puede ejecutar la optimización que mejores resultados brinda .Esto puede parecer desalentador a simple vista, pero miremos desde este punto de vista: VFP es una colección de funciones de acceso a datos escritas en C++ (posiblemente con algunos segmentos de assembler). Ninguno de nosotros podrá escribir algo mejor. Por lo tanto, se pude asumir sin dudas que el uso de índices que hace VFP al optimizar las consultas es el mejor posible. Teniendo esto siempre en mente, al programador sólo le queda diseñar cuidadosamente el conjunto de índices a utilizar en función de las consultas esperadas del sistema.
SYS(3054) y el plan de acceso
El plan de acceso en FoxPro - que en nuestro caso es sinónimo de cómo se efectúa optimización - puede averiguarse con la función SYS(3054). Por ejemplo, veamos un sencillo caso de consulta simple.
SELECT * FROM solic WHERE nrorec="00001452"
Donde se ejecuta una consulta sobre la tabla SOLIC.DBF, que por ahora no tiene ningún índice. Veremos estos distintos casos.
Activemos primero la exhibición del plan de acceso. La función SYS(3054,x) tiene un argumento segundario, x, el cual puede tomar los siguientes valores:
- 0 = no se muestra el nivel de optimización.
- 1 = sólo se muestra el nivel de optimización de cláusulas FOR, y de cláusulas WHERE que no incluyan combinaciones entre tablas, es decir , de selección (filtrado) de datos.
- 2 = se muestran niveles de optimización para filtros y para combinaciones indistintamente.
Filtrado de tablas
En álgebra relacional existe el operador de selección, el cual indica la operación de selección de registros o filas (la letra griega sigma es la "s"), y se aplica a la operación de filtrado de tablas - es decir, selección de registros. Por ejemplo, para indicar en álgebra relacional la selección de el registro de la tabla SOLIC que tenga el numero de recibo igual a "00001452", indicaríamos así:

El comando equivalente de SQL para esa operación de selección sería:
SELECT * FROM solic WHERE nrorec="00001452"
donde se impone un filtrado a la tabla. Para ver si se utiliza o no el índice, debemos usar la función SYS(3054). Coloquemos pues =SYS(3054,2) en la ventana de comandos para activarla y observemos lo que sucede:
Ejecutemos
SELECT * FROM solic WHERE nrorec="00001452".
Al no tener índices, no existe ningún tipo de optimización, en la ventana del escritorio de VFP se devuelve lo siguiente:
Nivel de optimización Rushmore para tabla Solic: nada
Ahora impongamos un índice para la columna liquid mediante
INDEX ON nrorec TAG nrorec
El índice puede ser de cualquier clase, no necesariamente compacto CDX. Una vez indexado, reemitamos la consulta
SELECT * FROM solic WHERE nrorec="00001452"
y podremos verificar este nuevo mensaje:
Utilizando indice de etiqueta Nrorec para optimizar con Rushmore tabla solic
Nivel de optimización Rushmore para tabla Solic: parcial
Como era de esperarse, se utiliza el índice para optimizar la consulta. Sin embargo, la optimización no es completa porque el filtro se impone utlizando el índice y la marca de borrado, que se evalúa siempre que SET DELETED esté en ON, como es nuestro caso en la mayoría de las veces. Por ello, al estar SET DELETED ON, VFP agrega internamente una cláusula AND NOT DELETED() a la consulta. Como no existe el índice sobre DELETED(), la optimización es parcial.
Verifiquemos esto. Coloquemos SET DELETE OFF y reemitamos la misma consulta. Esta vez el resultado arroja:
Utilizando indice de etiqueta Nrorec para optimizar con Rushmore tabla solic
Nivel de optimización Rushmore para tabla Solic: completo
Nótese que al no tener que evaluar la marca de borrado, VFP impuso el filtro para armar la consulta exclusivamente basándose en el índice sobre la columna NROREC, por lo tanto, la optimización fué completa.
- Ahora coloquemos SET DELETE ON nuevamente, como ocurre con la mayoría de nuestros sistemas - pensemos que serían poco útiles si no ignorasen la marca de borrado. Con este ajuste en ON, indexemos ahora por la marca de borrado a través de esta sentencia:
INDEX ON DELETED() TAG Deltd
NOTA: Si bien el nombre del tag puede ser "deleted", como en este ejemplo:
INDEX ON DELETED() TAG deleted
autores como Pat Adams, una de las gurúes de FoxPro 2.x, desaconsejaban este comportamiento, en parte para mantener al máximo la portabilidad del código (dBASE IV no era tan indulgente como FoxPro en el uso de las palabras reservadas, así como otros lenguajes tampoco).
Con el índice sobre la marca de borrado ya impuesto, se reemite la consulta, y el resultado es ahora -con SET DELETE ON - el mismo que se obtuvo con [SET DELETE OFF y sin índice sobre DELETED]
Utilizando indice de etiqueta Nrorec para optimizar con Rushmore tabla solic
Nivel de optimización Rushmore para tabla Solic: completo
Se tiene una optimización completa, ya que se utilizan ambos índices para la consulta. En este caso, la cláusula where queda escrita de la siguiente manera:
SELECT * FROM solic WHERE nrorec="00001452" AND NOT DELETED()
donde
nrorec="00001452"
es la condición colocada por nosotros en el código, y
AND NOT DELETED()
es la condición agregada por VFP automáticamente al estar SET DELE ON.
Cuando se tiene un operador AND, el optimizador interrumpe la evaluación cuando el primer operando devuelve FALSE, es decir, cuando nrorec no es igual a "00001452", se descarta la fila, y ni siquiera se evalúa la marca de borrado.
NOTA: Cabe preguntarse entonces si no sería mejor ubicar NOT DELETED() delante y nrorec="00001452" después, de tal forma que sea la marca de borrado la que se evalúe primero. Esto no sería conveniente porque existen muchos menos registros que cumplan la condición nrorec="00001452" que registros que cumplan la condición DELETED(). De esto deducimos que siempre conviene colocar la condición más restrictiva al comienzo de la cadena de ANDs, a fin de minimizar el tiempo de proceso de VFP al evaluar la condición lógica. El disponer así la cláusula FOR o WHERE es tarea del programador, y es un ejemplo más de optimización explícita a cargo de nosotros. En bases de datos servidoras, este reacomodamiento está a cargo del optimizador automático, ya que a través de estadísticas y de las características de las tablas, saben cuál de las condiciones será la más restrictiva. Por ejemplo, un gestor avanzado de BD colocará primero una condición que afecte una clave primaria - sólo habrá como máximo una coincidencia.
VFP y Select-SQL filtrado
Cuando se efectúa una consulta SELECT-SQL con una condición de filtro, es probable que VFP haga esta operación:
- Se abre la tabla de origen en otra área seleccionada en el momento. No es posible predecir el área de trabajo que VFP seleccionará para ejecutar el equivalente a un USE .. AGAIN NOUPDATE
- Se impone un filtro sobre la tabla recién abierta utilizando el índice. De no existir el índice ,se indexa temporalmente basándose en si conviene o no hacerlo por mediciones de procesador, memoria, etc.
- Como resultado, se obtiene un cursor de sólo lectura. Este cursor está asociado a una tabla subyacente, por eso para evitar cambios en entornos multiusuarios se marca el cursor como sólo lectura (ver NOUPDATE).
La operación es muy rápida porque no hay transferencia de información de la tabla de origen al cursor de resultados, simplemente se vuelve abrir la tabla en otra área de trabajo. La imposición del filtro sobre el índice es extremadamente rápida.
Si no se desea que se utilice este mecanismo, debe adicionarse la cláusula NOFILTER en SELECT-SQL, entonces efectivamente se crea un cursor independiente en el directorio indicado por SYS(2023). Este cursor, por compatibilidad, seguirá siendo de sólo lectura. Sin embargo, es probable que nunca se grabe en el disco sino en el caché administrado por VFP. Hasta tamaños de cursores igual a un 25% de la memoria RAM física, el cursor se mantendrá en la memoria. La función DBF() ejecutada con el alias del cursor como argumento devolverá una información de archivo que es inexistente. Es por esta razón que cuando uno cierra el cursor, no quedan rastros de él en el directorio SYS(2023): sencillamente, nunca se grabó físicamente nada allí.
En versiones de FoxPro 2.x donde la clausula NOFILTER no está disponible, debe adicionarse un campo calculado o virtual a la consulta para impedir que FoxPro utilice el mecanismo de filtrado y USE..AGAIN NOUPDATE. Supongamos que deseamos ejecutar esta consulta.
SELECT * FROM artic WHERE codrub+codart="01"
como vimos, esto será una consulta filtrada con USE..AGAIN NOUPDATE.
Si deseamos evitar que se use el filtro, podemos digitar
SELECT *,.F. AS otrocampo FROM artic WHERE codrub+codart="01"
con ello FoxPro creará otro cursor en el directorio SORTWORK o en su defecto en TMPFILES. Si no hay nada especificado en esas variables de entorno DOS, entonces se usará el mismo directorio donde residen los programas en ejecución - lo que no es muy recomendable porque hay que efectuar su remoción manualmente.
Reunión (combinación) de tablas y su optimización.
El álgebra relacional contempla otra operación básica: la reunión de tablas (JOINs). Para que la operación de reunión pueda darse, es necesario que exista un condición de reunión. Por ejemplo, existe una tabla EMPLEADOS y una tabla DEPARTAMENTOS (el viejo ejemplo). Para efectuar una reunión, es necesario que existan al menos una columna en común en cada tabla. Supongamos que esta columna en común sea empID (identificador de empleado), y que la misma exista en ambas tablas.
La reunión de EMPLEADOS (E) y DEPARTAMENTOS (D) sobre la columna empID quedaría expresada en álgebra relacional como:
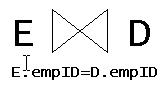
donde la condición de reunión es E.empID=D.empID. Como la condición de reunión es una igualdad, entonces se tiene la llamada equi-join. El comando SQL que materializa la reunión sería:
SELECT E.*,D.* FROM empleados E INNER JOIN departamentos D ON E.empID=D.empID
que es la sintaxis correcta para la reunión. También se permite la denominada reunión implícita, que se da cuando la condición de reunión va en la cláusula WHERE de la consulta:
SELECT E.*,D.* FROM empleados E,departamentos D WHERE E.empID=D.empID
NOTA: El álgebra relacional no indica cuál condición de comparación se debe usar en la condición de reunión. Incluso puede utilizarse un operador que no sea el signo igual, es decir, se permiten reuniones de no sean equi-join. Por ejemplo: cuya consulta equivalente sería:
SELECT E.*,D* FROM empleados E INNER JOIN departamentos D ON E.empID<D.empID
cuya utilidad es cuestionable, pero que está permitida.
Si E y D sólo tiene un sólo campo en común tal como empID, uno está habilitado a escribir la operación sin necesidad de especificar la condición de reunión, se sobreentiende que es sobre el campo en común:
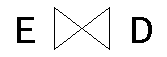
Si existiesen más de un campo en común, y la reunión se efectuase sobre todos los campos en común que tienen ambas tablas, se tiene la llamada reunión natural (natural join). En este caso, como empID es el único campo en común. Se supone que todas las operaciones de reuniones naturales se efectúan con el operador signo igual.
¿Cómo se ejecuta una operación de reunión?
Supongamos que exista una tabla Artículos (A) de 1000 registros, y una tabla Rubros (R) de 20 registros. Para que exista una reunión, digamos que la cláusula WHERE sería:
SELECT * FROM articulo A, rubros R WHERE a.codrub=r.codrub
donde codrub es código de rubro. Las operaciones que realiza un motor de base de datos para dar cumplimiento a las operaciones relacionales se constituyen la "implementación de operadores relacionales", y los métodos posibles son los siguientes:
1. Reunión por registros (sin índices) (muy ineficiente)
Por cada fila de una tabla, se escanean todos los registros de la otra, preguntando en cada caso si existe la condición de reunión en TRUE. Lo describimos así:
- Para cada registro de la tabla A, hacer:
- Para cada registro de la tabla R, hacer:
- si A.codrub==B.codrub entonces adicionar (A,R) al conjunto de resultados
Es decir: para cada fila en la tabla externa A, nosotros escaneamos enteramente a la tabla interna R. El costo de la consulta será:
Costo = 1000 + 1000 * 20 = 21.000 operaciones de I/O.
Como se puede apreciar, esta implementación es extraordinariamente ineficiente, y sólo sirve para indicar la base o esqueleto de los algoritmos que siguen a continuación, los que son todos derivados de éste.
2. Reunión por páginas (sin uso de índices)
Una forma de reducir las operaciones de I/O es paginar el archivo. Luego, se gasta 1 operación de I/O por cada página, y no por cada registro. Supongamos que cada página tenga 20 registros, entonces la tabla Articulos tendrá 500 páginas, y la tabla Rubros tendrá 1 página:
- Para cada página de la tabla A, hacer:
- Para cada página de la tabla R, hacer:
- Para cada registro de la página A, recuperar todos los registros de la página B que cumplan la condición de A.codrub==B.codrub, y pasar estos registros al conjunto de resultados.
El costo de la consulta será:
Costo = 500 + 500 * 1 = 1000 operaciones de I/O.
Compárese este resultado con el de 21.000 operaciones anterior. La posición en la cláusula WHERE no es conmutativa, es decir, no es lo mismo WHERE a.codrub=r.codrub que r.codrub=a.codrub. Veamos porque (la tabla externa es la que está a la izquierda):
- Para Artículos como tabla externa y Rubros como tabla interna el costo será de 500 + 500 * 1 = 1000 operaciones I/O
- Para Rubros como externa y Artículos como interna, el costo será de 1 + 500 * 1 = 501 operaciones I/O
Es fácil deducir que nosotros deberíamos colocar como tabla externa a la que tiene la menor cantidad de registros (es decir, de páginas, porque todas las páginas tienen el mismo tamaño para un mismo tipo de tablas). Con VFP uno puede pensar que debería poner un poco de atención en este sentido, pero no hay cuidado: Rushmore se encargará de colocar como tabla externa la de menor cantidad de páginas por nosotros. Eso lo puede averiguar rápidamente con RECCOUNT(), que es una medida linealmente proporcional al número de páginas. Sólo le bastará saber cual tabla tiene el menor RECCOUNT() para colocarla como externa.
Tambén en las bases de datos cliente-servidor el optimizador se encarga de averiguar cuál tabla conviene que sea la externa independientemente de cómo haya sido escrita la consulta. Sin embargo, la información que este tipo de bases de datos evalúan para su decisión es significativamente mayor que VFP - por ejemplo ,llevan registros de estadísticas y patrones de planes de acceso, etc.
Uno podría preguntarse qué ahorro hacemos si estamos leyendo menos páginas que cada página tiene más información que un registro. Como el número de bytes transferidos es igual para ambos casos (por registros o por páginas), uno podría cuestionar seriamente la ventaja de utilizar páginas. La respuesta es que el costo de leer una página es sensiblemente igual al de leer un registro (*). Una vez que el canal del subsistema de disco está abierto y recuperando datos, es necesario que lo mantengamos abierto la mayor cantidad de tiempo posible para "gastar" el costo de la lectura de una sola vez. En otras palabras, no es lo mismo abrir 21.000 veces la lectura al disco que abrirla 1000 veces - aunque exista caché de disco, ya que el impacto de éste beneficiará tanto a la primera opción como a la segunda. Asimismo, el caché del disco puede ser casi inútil si la tabla está muy desordenada, porque los datos están muy alejados unos de otros.
(*)NOTA: cabe distinguir entre páginas de las tablas de bases de datos -gestionadas por el motor de base de datos- y páginas del sistema de archivos (file-systems) -gestionadas por el sistema operativo, los cuales no tienen porqué coincidir. En estas líneas, nos referimos al primer tipo de páginas - de tablas.
Comentarios sobre la captación previa
En adición, Visual FoxPro, así como casi todas los demás gestores, lee mas páginas que las que necesita. Esto es así porque estadísticamente es muy probable que de necesitarse datos adicionales, éstos se encuentren en las páginas vecinas. Este mecanismo se llama "read-ahead", su sinónimo "pre-fetching", y la traducción aproximada sería captación previa. Algunos gestores avanzados permiten "afinar" el mecanismo de captación previa, y configurar su tamaño optimo en base a asistentes.
El tamaño de captación previa viene dado por 2 parámetros: la cantidad de páginas que se leen en adelanto, y el tamaño de las páginas. La IBM DB/2 permite configurar estos parámetros cuando se está creando la base de datos. Para darse una idea, en una máquina con 500MHz, más de 64MB de memoria, acceso promedio al disco mejor que 10ms, la IBM DB/2 recomienda leer 32 páginas de 16KB cada una en adelanto. Si la máquina tiene un procesador más lento o menos memoria, se sugieren 32 páginas de 4 KB cada una. Esta configuración se hace al crear la base de datos, una vez creada es difícilmente alterable.
VFP no permite cambiar este comportamiento, como tampoco SQL Server. La filosofía de Microsoft -explícitamente declarada por ellos- pasa por dejar al gestor manejar estos parámetros, ya sea prefijados o calculados en tiempo real de acuerdo a cada máquina donde corre el software, como lo hace SQL Server (es una filosofía de "nadie sabe más de nuestros productos que nosotros").
SQL Server manejará autónomamente la captación previa, debido a su excelente sinergia con el sistema operativo Windows NT/2000, se garantiza que las "decisiones" que SQL Server tome serán óptimas. En tal sentido, podemos asegurar que ciertamente los ingenieros de Redmond hicieron un gran trabajo, porque el rendimiento de SQL Server 2000 es de primera categoría.
Como podemos deducir, la captación previa reduce significativamente el tiempo de reunión si el archivo está ordenado - o al menos gran parte de él. Por ello, es una buena práctica mantener una política de ordenamiento con SORT por la clave más accedida en nuestro sistema. La operación de SORT puede hacerse aún con archivos de origen en uso, pero cuando se renombren los archivos recién ordenados, deberemos cerrar aquellos. Asimismo, se deberán reconstruir los índices de las nuevas tablas. Por lo tanto, esto no es convieniente hacerlo en una base diaria, sino más bien semanal o mensual.
Tipos de discos y captación previa.
Los discos rígidos IDE (integrated drive electronics) no son adecuados para entornos multiusuarios, ni siquiera adicionando grandes cantidades de memoria al servidor. Esto es así porque la norma no prevé resolución de peticiones múltiples, sino que simplemente las atiende en forma secuencial provocando el famoso cuello de botella o "contención multiusuaria".
Los discos SCSI (small computer systems interface) prevén la resolución de multiples peticiones de lectura-escritura mediante la puesta en cola por el firmware de la controladora. Es decir, el hardware SCSI es lo suficientemente inteligente para optimizar el acceso al disco en entornos multiusuarios. Por ello, siempre que se tenga una base de datos multiusuaria, el disco a elección es sin duda el SCSI.
Si bien los discos IDE tienen una tasa de transferencia equivalentes a los SCSI, la resolución por hardware de la cola de espera que tienen éstos últimos hacen que la performance en multiusuario sea perceptiblemente mejor en los SCSI. En otras palabras, siempre que se pueda, debemos tener un servidor con discos SCSI - no con IDE.
La captación previa minimiza en algo el problema de lectura (consultas) con los discos IDE, ya que disminuye efectivamente la cantidad de veces que se accede al disco. No hay que confundir captación previa con búfer de la base de datos, este ultimo tiene otro cometido.
3. Reunión por lazos anidados indexados (por registros indexados)
Es un derivado de la opción 1 y consiste en hacer la tabla interna aquella que tenga un índice sobre la condición de reunión. Es decir, supongamos que la tabla R tiene un índice sobre el campo codrub, entonces la operación sería (asumimos que Artículos es la tabla externa):
- Para cada registro de la tabla A, hacer:
- ubicar en la tabla R con búsqueda sobre índice la clave A.codrub
- si se encuentra, entonces pasar (A,R) al conjunto de resultados
Nótese que en este método no sirve de mucho tener un índice sobre la tabla A, porque sólo se utiliza el índice de la tabla interna - rubros R. Este es básicamente el tipo de optimización que Visual FoxPro utiliza en las operaciones de reunión JOIN, como veremos enseguida con SYS(3054,2).
El costo de la operación sería, asumiento Artículos como externa y Rubros como interna (que es la que tiene el índice):
Costo = 500 + (500 * 20 * costo de encontrar las filas coincidentes en R a través del índice)
Por cada fila de Artículos, el costo de encontrar la entrada en el índice de Rubros será de:
- Para índices clustered: 1,2 I/O (típico). VFP no utiliza índices clustered, entonces...
- "...Para índices B-Tree será de 2 a 4 I/O. VFP utiliza una variante del árbol B, llamado árbol B*, o B tree modificado, por lo tanto la performance estará más cerca de este valor.
Una vez encontrado dentro del índice R el dato deseado, el costo de capturar el dato de la fila exactamente coincidente en la tabla Rubros será de:
- Para indices clustered se consume típicamente 1 operación I/O para la consulta completa.
- Para índices normales se pueden consumir hasta 1 operación de I/O por cada fila encontrada (peor escenario).
Nótese la gran diferencia de entre un índice clustered y otro que no lo es. Si esto no quedó muy claro, hagamos unos números:
- Indice clustered, Artículos es tabla externa y Rubros es interna:
- SCAN de Artículos: 500 operaciones de I/O (500 páginas en artículos)
- Por cada fila en Artículos: 1,2 I/O para encontrar la página del índice donde reside el dato, más 1 I/O para recuperar la fila exactamente coincidente en Rubros.
- Costo total entonces es 500 * (1,2+1) = 1100 operaciones de I/O
- Indice clustered, Rubros es tabla externa y Artículos es interna:
- SCAN de Rubros: 1 operación de I/O (1 página)
- Por cada fila en Rubros: 1,2 I/O para encontrar la página del índice donde reside el dato, más el costo de recuperar las filas coincidentes en Artículos. Asumiendo una distribución uniforme (es decir, hay 1000 artículos / 20 rubros=500 artículos por rubro), el costo de recuperarlas será 1 ó 500 I/O dependiendo si el índice es clustered o no.
- Costo total es entonces: (a) con R externa, mejor caso: 1*(1,2+1) = 2,2 I/O, (b) con R interna, peor caso: 1 * (1,2 + 500) = 501,2 de operaciones I/O.
Como se ve, sigue siendo conveniente el uso de la tabla externa con la menor cantidad posible de filas.
4. Reunión por ordenamiento y combinación (sort-merge join)
Aquí el truco consiste en ordenar Artículos y Rubros por el campo en común (CODRUB). Luego se escanean las tablas para hacer una combinación (sobre la columna en común CODRUB), y rescatar las filas coincidentes. El motor de bases de datos hace lo siguiente:
* Seudocódigo de reunión por ordenamiento y combinación en VFP.
* Esto no es un código válido, sino uno para entender fácilmente el algoritmo
* que utilizan la mayoría de las RDBMS.
* Se asume que tanto ARTICULOS (A) y RUBROS (R) están ordenados sobre el campo
* en común CODRUB
* Primero vamos al primer registro de ambas tablas.
GO TOP IN R
GO TOP IN A
* Comenzar el proceso
DO WHILE NOT EOF("R") AND NOT EOF("A")
DO CASE
CASE R.codrub=A.codrub && si son iguales llamar al procedimiento CARTESIANO
DO Cartesiano && ver el esqueleto del procedimiento más abajo
CASE R.codrub > A.codrub && si clave izquierda > clave derecha, avanzar en tabla derecha
SKIP IN A
CASE R.codrub < A.codrub && si clave izquierda < clave derecha, avanzar en tabla izquierda
SKIP IN R
ENDCASE
ENDDO
* en este punto el resultado debe estar competo
*******************
PROCEDURE Cartesian
*******************
lVal=R.codrub && toma el valor de clave de la table externa
DO WHILE R.codrub=lVal
Aquí va el código para almacenar la fila en R al cursor temporal RT de resultados
SKIP IN R
ENDDO
DO WHILE S.codrub = lVal
Aquí va el código para almacenar la fila en S al cursor temporal ST de resultados
ENDDO
Aquí va el código para calcular el producto cartesiano de los cursores temporales RT y de ST
RETURN
* Esto no es un código válido, sino uno para entender fácilmente el algoritmo
* que utilizan la mayoría de las RDBMS.
* Se asume que tanto ARTICULOS (A) y RUBROS (R) están ordenados sobre el campo
* en común CODRUB
* Primero vamos al primer registro de ambas tablas.
GO TOP IN R
GO TOP IN A
* Comenzar el proceso
DO WHILE NOT EOF("R") AND NOT EOF("A")
DO CASE
CASE R.codrub=A.codrub && si son iguales llamar al procedimiento CARTESIANO
DO Cartesiano && ver el esqueleto del procedimiento más abajo
CASE R.codrub > A.codrub && si clave izquierda > clave derecha, avanzar en tabla derecha
SKIP IN A
CASE R.codrub < A.codrub && si clave izquierda < clave derecha, avanzar en tabla izquierda
SKIP IN R
ENDCASE
ENDDO
* en este punto el resultado debe estar competo
*******************
PROCEDURE Cartesian
*******************
lVal=R.codrub && toma el valor de clave de la table externa
DO WHILE R.codrub=lVal
Aquí va el código para almacenar la fila en R al cursor temporal RT de resultados
SKIP IN R
ENDDO
DO WHILE S.codrub = lVal
Aquí va el código para almacenar la fila en S al cursor temporal ST de resultados
ENDDO
Aquí va el código para calcular el producto cartesiano de los cursores temporales RT y de ST
RETURN
La tabla R se explora una sola vez, mientras que cada grupo de A se explora para cada fila coincidente en R. La presencia de un búfer ayudará mucho en las múltiples exploraciones sobre A. Por favor, recuerde que el código expuesto indica sólo una aproximación y no se ejecuta en VFP, sino que representa a grandes rasgos el proceso que corren varias funciones de la biblioteca en C++ dentro de VFP.
Si bien puede parecer un poco complicado, digamos que esta técnica se usa en casi todas las RDBMS conocidas. Como se necesitan tablas ordenadas para esta técnica, y VFP no ordena físicamente las tablas a menos que usemos el comando SORT, es que se necesitan utilizar los índices para realizar este ordenamiento. VFP usa los índices para lograr este cometido. Las bases de datos cliente servidor aprovechan el ordenamiento de los índices clustered, y de no poder hacerlo, utilizan los índices regulares para hacer aparecer a los archivos como ordenados. Por supuesto, los índices deben existir en las columnas en común que definen la operación de JOIN. De no existir, se evalúa la conveniencia de crearlo temporalmente. Véase este ejemplo, donde las filas coincidentes están coloreadas de igual forma:

- Nótese que el rubro 22 no tiene coincidencias en Articulos, luego no se producen filas coincidentes en codrub=22.
- El codrub=28 tiene dos coincidencias en artículos, luego se junta el registro 2 del Rubro con el 2 y 3 de artículos.
- A continuación, el codrub=31 tiene tres coindidencias en Artículos. Se junta el registro 3 de Rubro con el 3,4,5 de Artículos.
- Y así sucesivamente. Nótese que el escaneo de R es efectivamente uno solo, mientras que A se escanea repetidas veces, una por cada fila coincidente de R.
En nuestro ejemplo de tablas ficticias:
M = cantidad de páginas de la tabla externa RUBROS= 1 página (de 20 registros = 20 registros en Rubros)
N = cantidad de páginas de la tabla interna ARTICULOS = 500 páginas (de 20 registros = 1000 registros en Artículos)
Costo = M * log2 M + N * log2 N + (M + N) para sort-merge join
Si entrar en detalles pesados, el logaritmo (en base 2) aparece porque está asociado a la búsqueda binaria en un archivo. Básicamente entonces, el costo sería:
Costo = 1 * log2(1) + 500 * log2(500) + (1 + 500) = 4984 operaciones de I/O
Joins en VFP: descubriendo a Rushmore
Veamos entonces una operación de JOIN entre 2 tablas:
- SOLIC.DBF es una tabla de 600.000 registros, contiene solicitudes médicas. La tabla no cabe en la memoria, para evitar el efecto de los cachés.
- PROFESIO.DBF es una tabla sólo 42 registros, contiene la información de los profesionales.
- El campo en común es MATRICULA, de 6 caracteres
Y el resultado es de lo más interesante: VFP efectivamente selecciona la tabla externa con menor cantidad de filas, al estilo de sus hermanas mayores.
La consulta en cuestión es la siguiente:
SELECT a.matricula,b.prof_nombr FROM solic a,profesio b WHERE a.matricula=b.matricula
Las combinaciones posibles son: (a) con o sin índices, (b) con FROM solic,profesio y con FROM profesio,solic; y por último (c) con a.matricula a la izquierda y a la derecha del signo igual. Los resultados son los siguientes, promedio de 10 pasadas por cada tipo de consulta:
Ordenado físico
|
¿Indices?
|
FROM
|
WHERE
|
Tiempo
|
Ninguno
|
Ninguno
|
solictest a, profesio b
|
a.matricula=b.matricula
|
74.84
|
Ninguno
|
Ninguno
|
profesio b, solictest a
|
a.matricula=b.matricula
|
72.24
|
Ninguno
|
Ninguno
|
solictest a, profesio b
|
b.matricula=a.matricula
|
72.73
|
Ninguno
|
Ninguno
|
profesio b, solictest a
|
b.matricula=a.matricula
|
72.81
|
Nótese que indistintamente que cómo haya sido escrita la consulta, el tiempo es esencialmente el mismo. Esto significa que no importa cómo el programador coloque la sintaxis, el optimizador descompone la sentencia en elementos básicos y los reacomoda. La tabla externa debería ser la tabla PROFESIO, la cual es mucho menor que la tabla SOLICTEST. En este caso, el plan de acceso visible a través de SYS(3054) no reporta optimización alguna.
Veamos ahora la incidencia de los índices. Indexamos a SOLICTEST (tabla A) por la columna matricula, con un índice compacto CDX estructural regular. Una vez hecho eso, salimos de VFP para liberar los cachés de memoria, y volvemos a entrar. Con esto nos aseguramos que que Windows NT/2000 limpie los espacios de memoria de las aplicaciones cerradas, y al abrirlas no existe oportunidad alguna que vuelva a aprovechar cachés de aplicaciones anteriores, debido a que la reserva (allocation) de memoria se realiza previa escritura de un valor tal como &HF0 o &HFF en cada byte de memoria a ser asignada. Cuando la nueva instancia de VFP se abra, tendrá reserva de memoria libre de trazas anteriores. De otro modo, si corremos el proceso de medición apenas terminados los índices, éste se encontrará totalmente cacheado (recién fué creado), y por ello el rendimiento se verá distorsionado. Los resultados muestran una mejora significativa:
Ordenado físico
|
¿Indices?
|
FROM
|
WHERE
|
Tiempo
|
Ninguno
|
En tabla A
|
solictest a, profesio b
|
a.matricula=b.matricula
|
41.73
|
Ninguno
|
En tabla A
|
profesio b, solictest a
|
a.matricula=b.matricula
|
41.93
|
Ninguno
|
En tabla A
|
solictest a, profesio b
|
b.matricula=a.matricula
|
40.29
|
Ninguno
|
En tabla A
|
profesio b, solictest a
|
b.matricula=a.matricula
|
39.86
|
Ordenamos ahora ambas tablas sobre la columna matrícula, utilizando el comando SORT. Corremos ahora nuevamente la prueba, teniendo en mente que hemos ordenado físicamente la tabla A.
Ordenado físico
|
¿Indices?
|
FROM
|
WHERE
|
Tiempo
|
Tabla A
|
Ninguno
|
solictest a, profesio b
|
a.matricula=b.matricula
|
50.32
|
Tabla A
|
Ninguno
|
profesio b, solictest a
|
a.matricula=b.matricula
|
50.93
|
Tabla A
|
Ninguno
|
solictest a, profesio b
|
b.matricula=a.matricula
|
50.96
|
Tabla A
|
Ninguno
|
profesio b, solictest a
|
b.matricula=a.matricula
|
56.46
|
Nótese el gran aumento de velocidad en tablas sin indexar pero ordenadas. Se han ganado 22 segundos solamente por ordenar la tabla interna, la que tiene más cantidad de registros o páginas. Evidentemente, VFP efectúa algo parecido al sort-merge join, ya que éste se ve claramente favorecido por el ordenamiento físico.
Ahora indexamos sobre matrícula nuevamente, y corremos la prueba con índices y tablas ordenadas:
Ordenado físico
|
¿Indices?
|
FROM
|
WHERE
|
Tiempo
|
Tabla A
|
En tabla A
|
solictest a, profesio b
|
a.matricula=b.matricula
|
40.56
|
Tabla A
|
En tabla A
|
profesio b, solictest a
|
a.matricula=b.matricula
|
45.64
|
Tabla A
|
En tabla A
|
solictest a, profesio b
|
b.matricula=a.matricula
|
46.49
|
Tabla A
|
En tabla A
|
profesio b, solictest a
|
b.matricula=a.matricula
|
42.65
|
En este caso, el ordenamiento no aporta ventaja alguna sobre la prueba sin indexar. Evidentemente, el magistral manejo de los índices por Rushmore hace casi innecesario el ordenamiento físico, aún con tablas como la nuestra, de 600.000 registros.
Pongamos los resultados en un gráfico para visualizar mejor:

Como vemos, la optimización nos depara algunas sorpresas. La existencia de índices es mandatoria para obtener la máxima optimización posible. De no tener índices, se puede tener ganancia si se mantienen las tablas ordenadas por la condición de reunión.
LA MARCA DE BORRADO EN LA OPERACION DE REUNION
La marca de borrado tiene incidencia si la cantidad de registros marcados para borrado es significativa respecto a la cantidad de registros totales. En nuestras pruebas , la tabla A tenía 600.000 registros, sin ninguna marca de borrado. Por lo tanto, los números con o sin indexado sobre DELETED() fueron esencialmente idénticos.
600K registros, sin ninguna marca de borrado:
FROM
|
WHERE
|
Tiempo CON índice en DELETED()
|
Tiempo SIN índice en DELETED()
|
solictest a, profesio b
|
a.matricula=b.matricula
|
45.38
|
40.56
|
solictest b, profesio a
|
a.matricula=b.matricula
|
49.85
|
45.64
|
solictest a, profesio b
|
b.matricula=a.matricula
|
39.10
|
46.49
|
solictest b, profesio a
|
b.matricula=a.matricula
|
40.69
|
42.65
|
Para ver realmente cuán importante es la marca de borrado, borramos un 30% de la tabla SOLICTEST (A), y corremos nuevamente la prueba. Ahora existen 180.000 registros con marca de borrado, contra un total de 600.000. Los números obtenidos son los siguientes:
600K registros, 180K registros marcados para eliminación:
FROM
|
WHERE
|
Tiempo CON índice en DELETED()
|
Tiempo SIN índice en DELETED()
|
solictest a, profesio b
|
a.matricula=b.matricula
|
39.02
|
33.44
|
solictest b, profesio a
|
a.matricula=b.matricula
|
38.05
|
36.96
|
solictest a, profesio b
|
b.matricula=a.matricula
|
36.16
|
31.63
|
solictest b, profesio a
|
b.matricula=a.matricula
|
34.89
|
35.31
|
Y para redondear, borramos el 90% de la tabla, dejando sólo el 10% sin la marca de borrado. El tiempo de consulta es ahora:
600K registros, 540K registros marcados para eliminación:
FROM
|
WHERE
|
Tiempo CON índice en DELETED()
|
Tiempo SIN índice en DELETED()
|
solictest a, profesio b
|
a.matricula=b.matricula
|
21.96
|
27.17
|
solictest b, profesio a
|
a.matricula=b.matricula
|
21.51
|
26.71
|
solictest a, profesio b
|
b.matricula=a.matricula
|
21.32
|
27.08
|
solictest b, profesio a
|
b.matricula=a.matricula
|
22.19
|
26.52
|

La conclusión es que para grandes tablas, evidentemente el índice sobre DELETED() es irrelevante, contra lo que uno pudiera pensar. Asimismo, la ganancia de velocidad es proporcional (aunque no linealmente) a la cantidad de registros marcados para eliminación. Cuando la cantidad de registros marcados para eliminación es muy grande (90% de la tabla), recién se notó la ventaja del índice.
Conclusión
El corolario de todo esto puede resumirse en estos puntos:
- La optimización basada en índices es la mejor posible en VFP
- Si no existen índices, el ordenamiento regular sobre la clave más utilizada en los JOINs es lo más recomendable, sobre todo si son tablas de tamaño considerable.
- La optimización con índices es tan buena que el hecho que estén ordenadas físicamente o no pasa casi inadvertido.
- VFP altera el orden de los operandos en las cláusulas FROM y WHERE de SELECT-SQL, y también en las cláusulas FOR de comandos xBase optimizables.
- El índice sobre la marca de borrado aporta muy poco si la tabla es grande y el porcentaje de registros marcados para borrado es normal -menos de 30%. Con porcentajes mayores de 30% el rendimiento puede variar, y los índices se tornan útiles cuando la cantidad de registros eliminados es excesiva.
- La ganancia de velocidad es proporcional al porcentaje de registros marcados para eliminación (respecto a la tabla que no tiene ninguna fila marcada).
Bueno, eso es todo. Espero que nos podamos encontrar muy pronto para poder seguir compartiendo conceptos tan interesantes de nuestro querido Visual FoxPro. Hasta pronto.
Bibliografía comentada:
- "Visual FoxPro Developer's Guide", por Jeb Long, SAMS Publishing. Es un excelente libro que cubre la mayoría de los temas de Visual FoxPro. Basado en VFP 3.0, quizá su mejor parte resida en el comienzo, con una gran introducción en sus dos o tres primeros capítulos a la herencia y ascendencia de VFP, escrito por una leyenda viviente, Jeb Long, el creador del lenguaje xBASE, él mismo nos enriquece con sus muchos recuerdos acerca de cómo se implementó tal o cual comando en sus tiempos de Ashton-Tate. La trayectoria de 30 años del autor en el mundo de xBASE se hacen notar a cada capítulo. Con prólogo de David Fulton.
- "Database Management Systems" por Raghu Ramakrishnan y Johannes Gherke; McGrawHill. Provee información general sobre cómo funcionan las bases de datos. Algunos capítulos son sólo de interés académico, otros, en cambio, como los de SQL, son de uso universal para el programador que desea fortalecer su base teórica. Si bien no se hace notar ninguna inclinación por ninguna base de datos en particular, sospechamos que efectivamente hay grandes referencias al modo en que funciona el motor de base de datos de SQL Server. Repetimos, los programadores de VFP podemos vivir sin este libro, pero si alguien desea saber más sobre el detrás de la escena de las bases de datos cliente-servidor, debería darle una oportunidad a esta obra. CD con presentaciones de los capítulos para hacer demostraciones, y problemas resueltos.
- "FoxPro 2.5 Advanced Developer's Handbook, por Pat Adams y Jordan Powell. Hasta la aparición de VFP, este libro era el más avanzado que pudimos leer. Con gran conocimiento de trucos de programación y funcionamiento interno del motor de FoxPro 2.5, nos da la base necesaria para optimizar al máximo la velocidad en cualquier escenario. Provisto de un disco, se provee con un manejador de errores que contempla cada error en particular (FP2EROR.PRG). Es el único libro con ejemplos de contratos tipo para la ejecución de software en FoxPro. Si bien gran parte de las páginas se consumen en código que se provee en el CD, su lectura es altamente recomendable. Con prólogo de David Fulton.
Impresionante aporte, tantos años usando el amado Visual Foxpro sin saber estas cosas, muchas gracias por este excelente artículo.
ResponderBorrarMuy bueno, Excelente, Gracias !
ResponderBorrarEspectacular !!
ResponderBorrarMuy interesante, temas que aun nos ocupan y nos preocupan.
ResponderBorrar